显示仓库中的页面
1、把文件放在**.github.io仓库
2、在文件路径前面加http://htmlpreview.github.io/?
然后访问,如:
http://htmlpreview.github.io/?https://github.com/**/example/index.html
然后访问,如:
http://htmlpreview.github.io/?https://github.com/**/example/index.html
2017-09-25
今天在等电梯的时候,突然对电梯工作流程感兴趣,想写个电梯模拟小程序。
先来占个坑,写个大致思路,等考完试再来完成
//这楼有20层int max_floor = 20;
1 | //楼层 |
1 | //电梯 |
因为有两个电梯,所以把判断函数拿出来单独构造一个类。1
2
3
4
5
6//判断电梯哪个电梯去载人,上升还是下降
class select {
public:
//判断哪个电梯去载人
void which();
}
1 | void elevator::up() |
大致思路就先写到这,后续加上。
真的蛮好玩诶!
1.用户名密码登录
2.增删改查管理员发布的网页数据
1.对用户名数据进行哈希加密(签名)
2.强制登录页面(重定向)
3.浏览器与服务器传输数据
登录界面
首页

发布信息

用户评价

其功能是建服务器监听8080端口。
具体代码:
1 | var server=express(); |
1.解析请求数据
2.并发给请求方cookie,
3.声明调用的模板
4.路由功能,区分请求并转入相应界面
5.处理静态文件请求
该文件封装模板,其功能是将登录时的用户输入的用户名密码等数据用哈希算法加密(签名),让该数据不可见,避免他人获取用户名密码。
代码如下:
1
2
3
4
5
6
7
MD5_SUFFIX: '*****',
md5: function (str){
var obj=crypto.createHash('md5');
obj.update(str);
return obj.digest('hex');
其中,MD5_SUFFIX加在数据后面,再进行md5加密,该MD5_SUFFIX是自定义的数据的
在服务器运行后,服务器一直监听8080端口,当有请求访问,首先对该用户的登录状态和请求进行判定,如果不是管理
员,就重定向返回登录界面。如果想访问其他页面,也不行,重定向回登录界面。只有当既是管理员,请求访问的又是
登录界面才对请求予以响应。
1 | //检查登录状态 |
如果已确定是管理员,就再来判定其访问请求。
1 | //根据不同http请求,转向不同页面 |
那是怎么判断是否为管理员?
当管理员登录时,后台就拿着页面获取的用户名密码和数据库的进行比对,成功就给浏览器发session,不成功就不发,
判定管理员的时候就是看有没有session。
为什么不直接不直接用用户名密码验证,而要再加一个session?
session可以理解为cookie的加强版,具有生存期,可以控制用户在一定时间内免登陆。若采用用户名密码验证,那每
退一次,就得输入一次密码,这在实际操作中是很不方便的。
1 | if(data[0].password==password){ |
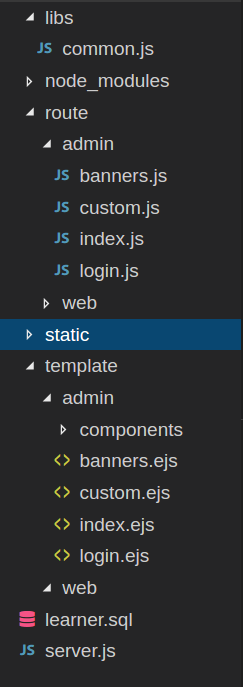
登录后,就对数据进行操作。route和template分别是存放js和静态文件的文件夹,文件夹内的js文件实现的功能相似,都是将页面和数据库连接起来,对数据进行增删改查的操作。就banners页面来说,其具体代码如下:
1 | //连接数据库 |
修改banner数据
1 | db.query(`SELECT * FROM banner_table WHERE id=${req.query.id}`, (err, data)=>{ |
使用hexo模块的时候,不小心将已经配置好的blog文件删除。在网上查找资料,运行npm cache clean –force,出现错误(不能使用hexo命令)。然后我就准备重装hexo,把usr/bin和local里hexo相关文件删除,用npm重新下载hexo,但还是和之前一样出错
需要删除hexo相关文件和packagejson里的依赖,再重新下载hexo,就可以使用了
具体位置(linux环境):/home/zaizizaizai/.npm-global/bin和/home/zaizizaizai/.npm-global/lib
补充:此路径为隐藏目录,在home区需要按快捷键ctrl+h显示隐藏文件,或者通过命令行进行操作
以下是自适应网页设计的方法:
在网页代码的头部,加入viewport元标签
<meta name="viewport" content="width=device-width, initial-scale=1" />
viewport是网页默认的宽度和高度,上面这行代码的意思是,网页宽度默认等于屏幕宽度(width=device- width),原始缩放比例(initial-scale=1)为1.0,即网页初始大小占屏幕面积的100%。
所有主流浏览器(IE9)都支持这个设置。对于老式浏览器(IE6、7、8),需要使用css3-mediaqueries.js。
若在头部加入了viewport元标签,网页会自动更具屏幕宽度调整布局,所以不能使用具有绝对宽度的元素。
即css代码不能制定像素宽度
width:xxx px;
只能使用百分比宽度
width: xx%;
或者
width:auto;
字体也不能使用绝对大小(px),而只能使用相对大小(em)。
1
2
3body {
font: normal 100% Helvetica, Arial, sans-serif;
}
上面的代码指定,字体大小是页面默认大小的100%,即16像素。
1
2
3 h1 {
font-size: 1.5em;
}
然后,h1的大小是默认大小的1.5倍,即24像素(24/16=1.5)。
1
2
3 small {
font-size: 0.875em;
}
“流动布局”的含义是,各个区块的位置都是浮动的,不是固定不变的。
1
2
3
4
5
6
7
8
9.main {
float: right;
width: 70%;
}
.leftBar {
float: left;
width: 25%;
}
float的好处是,如果宽度太小,放不下两个元素,后面的元素会自动滚动到前面元素的下方,不会在水平方向
overflow(溢出),避免了水平滚动条的出现。
“自适应网页设计”的核心,就是CSS3引入的Media Query模块。
它的意思就是,自动探测屏幕宽度,然后加载相应的CSS文件。
1
2
3<link rel="stylesheet" type="text/css"
media="screen and (max-device-width: 400px)"
href="tinyScreen.css" />
上面的代码意思是,如果屏幕宽度小于400像素(max-device-width: 400px),就加载tinyScreen.css文件。
1
2
3 <link rel="stylesheet" type="text/css"
media="screen and (min-width: 400px) and (max-device-width: 600px)"
href="smallScreen.css" />
如果屏幕宽度在400像素到600像素之间,则加载smallScreen.css文件。
除了用html标签加载CSS文件,还可以在现有CSS文件中加载。
1
@import url("tinyScreen.css") screen and (max-device-width: 400px);
同一个CSS文件中,也可以根据不同的屏幕分辨率,选择应用不同的CSS规则。
1
2
3
4
5
6
7
8
9
10 @media screen and (max-device-width: 400px) {
.column {
float: none;
width:auto;
}
#sidebar {
display:none;
}
}
上面的代码意思是,如果屏幕宽度小于400像素,则column块取消浮动(float:none)、宽度自动调节(width:auto),sidebar块不显示(display:none)。
除了布局和文本,”自适应网页设计”还必须实现图片的自动缩放。
这只要一行CSS代码:
img { max-width: 100%;}
这行代码对于大多数嵌入网页的视频也有效,所以可以写成:
img, object { max-width: 100%;}
老版本的IE不支持max-width,所以只好写成:
img { width: 100%; }
此外,windows平台缩放图片时,可能出现图像失真现象。这时,可以尝试使用IE的专有命令:
img { -ms-interpolation-mode: bicubic; }
或者,Ethan Marcotte的imgSizer.js。
1
2
3
4 addLoadEvent(function() {
var imgs = document.getElementById("content").getElementsByTagName("img");
imgSizer.collate(imgs);
});
由于多说、跟帖等评论插件都倒了,就转向了友言。结果友言服务器是国外的,得翻墙才能用。就转向了畅言,可是这
搜狐畅言得用域名(我怕还没来的及买域名了-_-)。最后还是回到大爱的git了。
过程:
多说、跟帖–>友言–>畅言–>gitment
2017-11-23
这是在我看完《深入理解MongoDB》后,按照自己的理解记录下来的笔记,初次接触,若有错误,敬请指出,感谢!
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB操作模式:
应用程序<=>mongos<=>集群
分片(sharding)是MongoDB用来将大型集合分割到不同服务器上采用的方法。这样做是为实现3个目标:
让集群“不可见”
让应用程序知道要执行任何“增删改查”操作只需要发送请求给MongoDB这一个对象就行了,剩下的事就交给它了,不需要区分交给那个服务器,简化了应用程序端操作指令。在MongoDB中具体连接客户端与服务器端的就是叫做mongos的专有路由进程,mongos可以比喻为一个秘书,转发客户端的请求,和服务器端的响应。
保证集群总是可以读写
一个大的集合分为多个分片(shard),当其中一个进程/服务器出现问题,由运行在其他分区的其他副本接替换掉的部分继续工作。
使集群易于扩展
将大的集群分割为多个小的分区,当需要资源的时候,只需要添加小的空间。
sharding操作后得到分片(shard)是集群中负责数据某一子集的一台或多台服务器。换言之,一个分片包含数据的某个子集。例如一个集群包含1000份代表网站注册用户文档,其中一个分片就可能包含200份。
若一个分片包含多个服务器,则每个服务器拥有一份完整的数据副本。
一分片一区间
分配数据最简单的方法就是让一分片负责一区间的数据。假设有四个分片,依次对应[“a”,”f”),[“f”,”n”),[“n”,”t”),[“t”,”{“)区间,{是ASCII码表中字母z后面的字符。许多用户用首字母在范围[“a”,”f”)中的名字来注册,就导致分片1较大,我们可以调整区间使分片1对应的区间缩小,从而让分片均衡。但当分片1和分片2过载时,就不太好处理。假设分片1和分片2各有500G数据,分片3和分片4各有300G数据,此时就需要分片1转移100G数据到分片2,接着从分片2转移200G数据到分片3,最后分片3转移100G数据到分片4,从而使每个分片都具有400G数据,达到均衡。这还只是4个分片,执行这个操作一共移动了400G数据。当考虑到所有分片,可想需要移动的数据量是很大的。
一分片多区间
重新来考虑上面的情况,此时是一分片多区间。我们可以把分片1和分片2都划分为两个区间,分片1分别对应包含400G数据的[“a”,”d”)区间和包含100G数据的[“d”,”f”)区间,分片2分别对应包含400G数据[“f”,”j”)区间和100G数据[“j”,”n”)区间。我们就可以把分片1中的[“d”,”f”)区间的数据直接移动到分片3,把分片2中的[“,j”,”n”)区间的数据直接移动到分片4,相比上一种情况,只需要移动200G数据。添加新的分片也具有同样的优势——减少数据转移量。
创建块
一个区间的数据成为一个数据块(也叫块,chunk),块默认大小为200MB(兼顾可移动性和最小开销),当一个块的区间一分为二是,就变成两个块了。当提到块出不得不说片键了,如下所示
{“username”:”gala”,”age”:21}
{“username”:”pinocchio”,”age”:25}
{“username”:”zaizizaizai”,”age”:16}
如果我们选择age字段作为片键病得到一个块区间[20,30),则得到的块为:
{“username”:”gala”,”age”:21}
{“username”:”pinocchio”,”age”:25}
可以把片键理解为一个选择器(标签),也可理解为属性,即挑选符合条件的数据,在这里不仅局限于把age作为片键,username也可以作为片键,且片键值不可修改。
随着数据的增加,当一个块变大,MongoDB会自动将其分割为2个小块。若分片间数据比例失衡,MongoDB会迁移块其他分片(由叫做平衡器的进程执行),以达到分片间数据比例总是平衡的状态。同时平衡器会忽略微小的不平衡,否则会导致恶性循环。
片键的选择很重要,因为这关系到读操作的速度。以下介绍集中片键的几个常见反例,以便更好理解片键选择。
小基数片键
假设我们有3个分片,我们需要选择片键。前后端编程开发常见的建站就需要对数据分类,有用户的数据、管理员的数据、网页参数的数据,那为了方便理解和区分,就选择用户、管理员、网页参数3个片键。虽然管理员数据比较小,但用户的数据会一直增加,增加到一定程度后,MongoDB也不能分割分片里的块了,最终磁盘空间被耗尽。由于片键值数量有限,后来,就会得到一个又大又无法移动,还不能分割的块,这对数据管理造成极大的不方便。
升序片键
对大部分应用程序而言,新数据被访问的次数总是多于老数据,所以人们会尝试诸如时间戳或者objectID一类的字段作为片键。比如,社交软件上的发动态,每条动态包含消息、地点、时间,我们以时间段来分片。从一个数据块开始,随着时间推移,一个块满了,裂变为两个块,时间点继续增加,这个片键创造了一个单一且不可分散的热点。动态被发出,该时间点MongoDB需要对该时间点对应的块进行写操作,而当大量的动态在同一时间发出,MongoDB来不及对块进行写操作,就会造成堵塞,使应用程序瘫痪。
随机片键
为了避免以上的热点片键,有人选择取随机的字段来分片。采用这种字段开始还不错,但随着数据量的增加,它会变得越来越慢。现在采用随机片键,已经得到一组均匀分布于各分片的数据块。假设分片上的一个块填满并分裂了,配置服务器注意到分片2比分片1多10个块,为了抹平差距,MongoDB就将分片2中的随机5个块(块的数据量的大小不确定)经由内存发送给分片1。随着数据量的增加,这5个随机的块的数据量会很大,应发大量的磁盘IO,致使数据库变慢。
好片键
准升序键加搜索键
快速起步
若想尽快上手,可用Github上的mongos-snippets,其中有个simple-setup.py能自动地启动、配置和生成一个集群,它需要MongoDB的Python驱动。
安装MongoDB的Python驱动
sudo easy_install pymongo
下载mongos-snippets库并执行以下操作
python sharding/simple-setup.py –path=绝对路径
simple-setup.py会启动一个mongos进程,地址为localhost://27017
2017.10.29 pinocchio
攻击方式重点:sql注入 xss
技巧:
1.数据库里的登录ID和昵称分开
2.1机密性
2.2完整性
2.3可用性
资产等级划分->威胁分析->风险分析->确认解决方案
3.1资产等级划分
3.2威胁分析
3.3风险分析
3.4确认解决方案
4.1Secure By Default原则
4.1.1黑名单、白名单
4.1.2最小权限原则
4.1.3纵深防御原则
4.1.4数据与代码分开原则
4.1.5不可预测性原则